by Michael Clements
 What is failure? We know that fan belts break, motors burn out, and power disruptions are an operational reality. But not all failures are equal. The first step in making it work is to define what failure looks like for your project.
What is failure? We know that fan belts break, motors burn out, and power disruptions are an operational reality. But not all failures are equal. The first step in making it work is to define what failure looks like for your project.
Failure is an unacceptable or unsustainable deviation from an operating condition. For example, losing a critical pressure relationship in a lab; having a breach of containment due to occupant error; or losing millions of dollars in research due to inadequate temperature control.
In each of these scenarios, there are building system components and occupant actions that might lend themselves to the failures described. This is important. Once potential types of failures have been defined, the next step is identifying all the known factors that might cause this failure. These are common-cause failures, and they’re the ones we expect. Typically these are easy to define: The component or standard operating procedures (SOP) breaks down, so it’s a failure. Since we’ve defined the component’s or SOP’s function as critical, we provide some form of redundancy to address this identified risk.
We also need to define special-cause failures: These are the ones we don’t expect. Some people call these “hurricane scenarios.” But that’s not always the case. Building systems are increasingly complex, and even though these systems might have standard components, they can still experience failures that are hard to predict. Think about it this way: As building systems become more complex, potential for failure increases. Additionally, due to system complexity, predicting the deviations gets harder.
Mapping all potential failures can be a daunting task. To avoid analysis paralysis, we need to temper these scenarios by assessing the risks and what’s realistic. Risk, in this context, is the consequence of an event multiplied by the probability of that event. Up until now, all we’ve talked about is the consequence, not the likelihood.
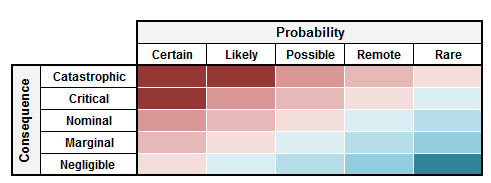
Going back to our common-cause failures (think: pumps, fans, actuators, human error, etc.), we can typically get away with a qualitative approach for assessing risk. This looks something like this:
By identifying the qualitative probability, we can determine the risk. Let’s say losing a pressure relationship between two spaces would be catastrophic, and we know that our exhaust fan is a critical component for avoiding that failure. Since fan failures are somewhere between remote and likely (depending on the type of fan, its drive configuration, etc.), it’s safe to say we have a nominal risk and we should apply some additional measures to mitigate this risk. In this case it could mean adding a redundant exhaust fan powered from a different electrical source. The qualitative approach can work well for these common-cause failures.
Special-cause failures need a more nuanced approach. This involves a quantitative approach where the probability is a numerical value. Imagine that you’re considering a project located in an area prone to hurricanes. The consequences, in this case, might include damage to the facility, sustained loss of power, flooding, and even complete loss of research. All these consequences come with a cost (not counting reputation, perception, etc.) that can be reduced based on the probability of that consequence occurring. Ultimately this can be weighed against the costs of any mitigating strategies (extra generator tank capacity, enhanced facility structure, etc.), and a cost-benefit analysis can be conducted.
As we consider solutions, it’s important to note that there are engineered solutions (building controls, widgets, interlocks, etc.) and there are SOP solutions. Engineered solutions are seen as repeatable, and thus reliable, but can come at significant costs and complexity. SOP solutions carry the risk of noncompliance, but leave room for adaptive decision-making, which has its benefits. The type of solution and its specifics need to be carefully weighed against the risks that you’re trying to mitigate. Typically a combined strategy provides the necessary protection, along with a degree of flexibility that can be advantageous. It all starts with a design that suits the risk assessment. So, when it comes to risk, don’t be too risky.

Michael Clements
Michael Clements, MBA, PE, LEED AP, is the regional director at Vanderweil Engineers in Atlanta.







